Git repositories
MLReef aims to solve collaboration, reuse and discoverability of ML functions. With this scope, MLReef is based on one side on git repositories (see: https://git-scm.com/) that provide you with sufficient flexibility and control over your source code.
Next to this, we split the Machine Learning life-cycle in two major consituents:
- ML projects that host your data, pipelines and models.
- AI Library that hosts your scripts, based on their functionality within the ML life cycle.
In the following section, we will go through each of these to see their purpose and function.
Repository types
As described, MLReef is split in two major sections:
- ML Projects
- AI Library
ML Projects
In these repositories you can upload your data and use the data pipelines and experiment pipelines as well as track your experiments and progress.
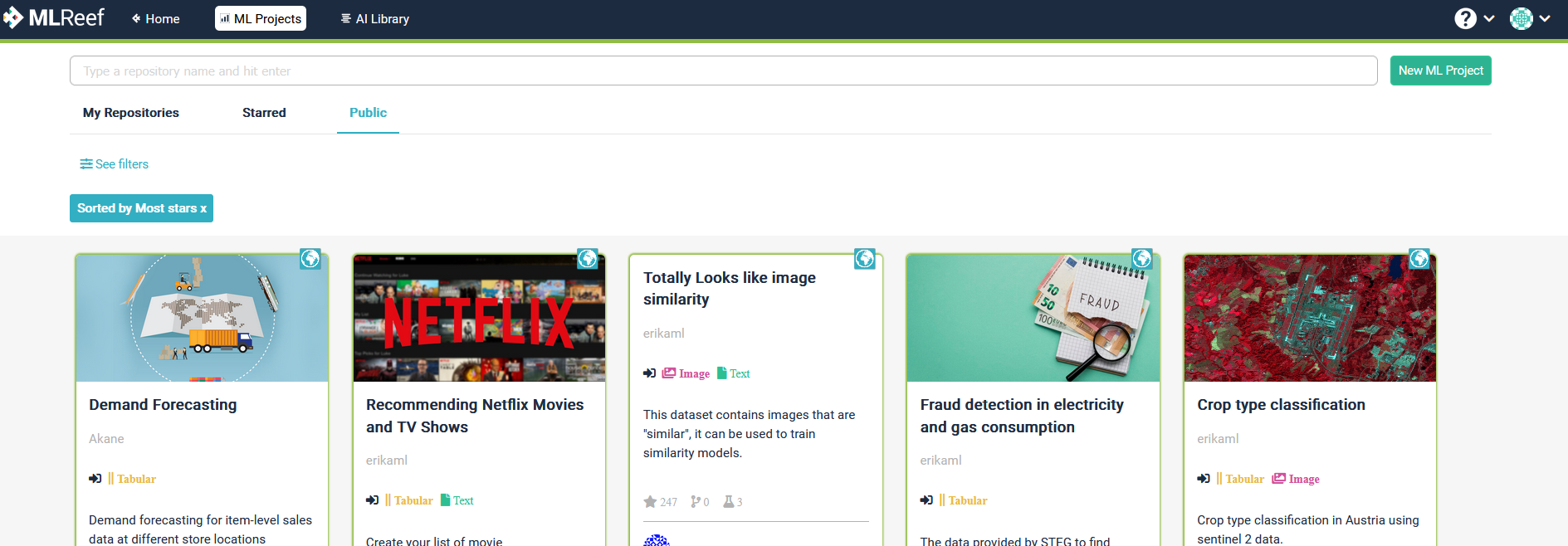
ML Projects are git repositories that will host:
- Your training, testing and validation data
- Your data pipelines
- Your experiment pipelines for model training
- Your experiments and models (model registry)
AI Library
The AI Library contains three classes of git repositories - we call them code repositories as they should only contain your code functions.
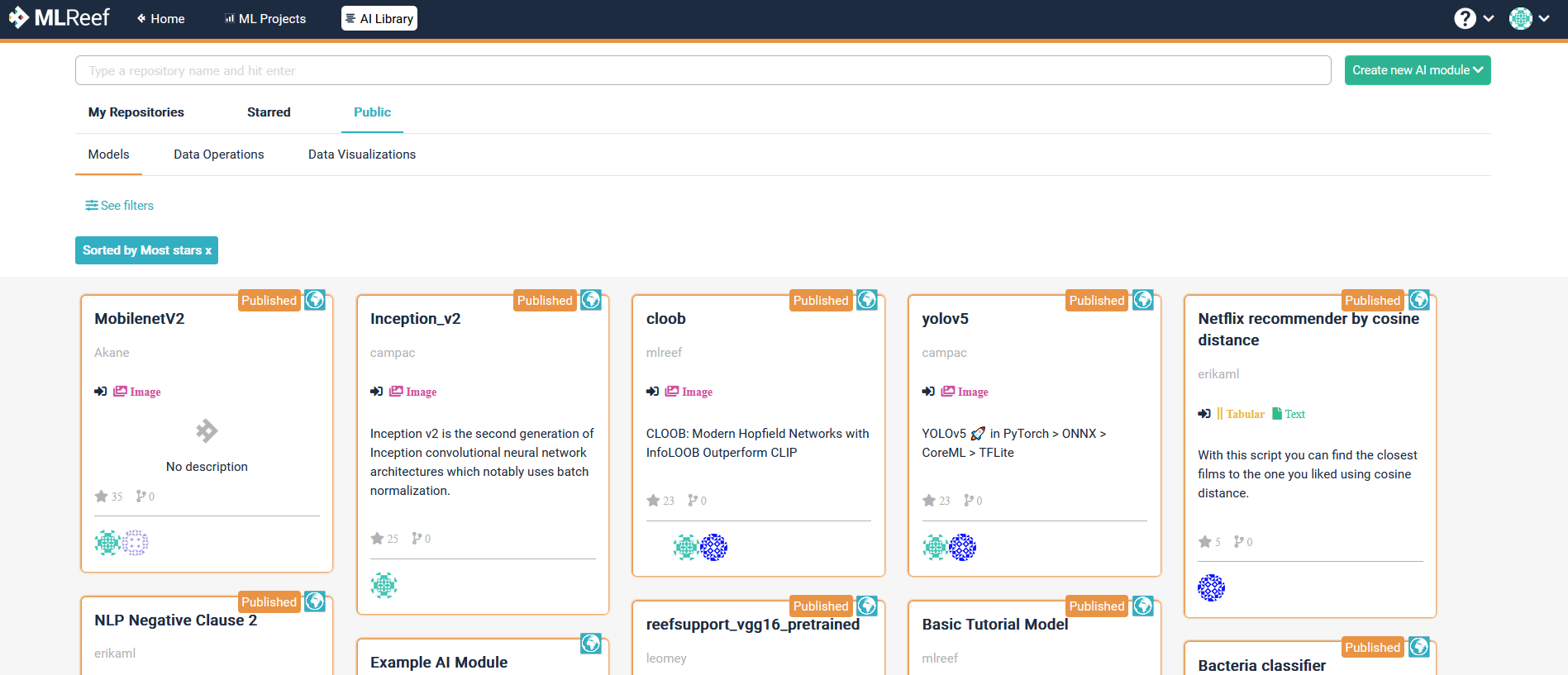
We currently have three classes of code-repositories, structured on their function within the ML life cycle:
- Models: To manage the source code of your algorithms.
- Data Operations: Functions and scripts for transforming your data (data pre-processing).
- Data Visualizations: Scripts to create simple or complex data visualizations.
Continue reading
| Relevant topics | Documentation for |
|---|---|
| ML Projects | Basic concepts of using ML Projects. |
| Code Repositories | From Models to Data Visualizations - how to create your own scripts. |
| Publishing Code Repositories | Converting git repositories to explorable and usable AI Modules in data pipelines. |